
灵闪的AI互联工具是干什么用的?具体应用场景是什么?
1 Answers
AI互联使用场景1
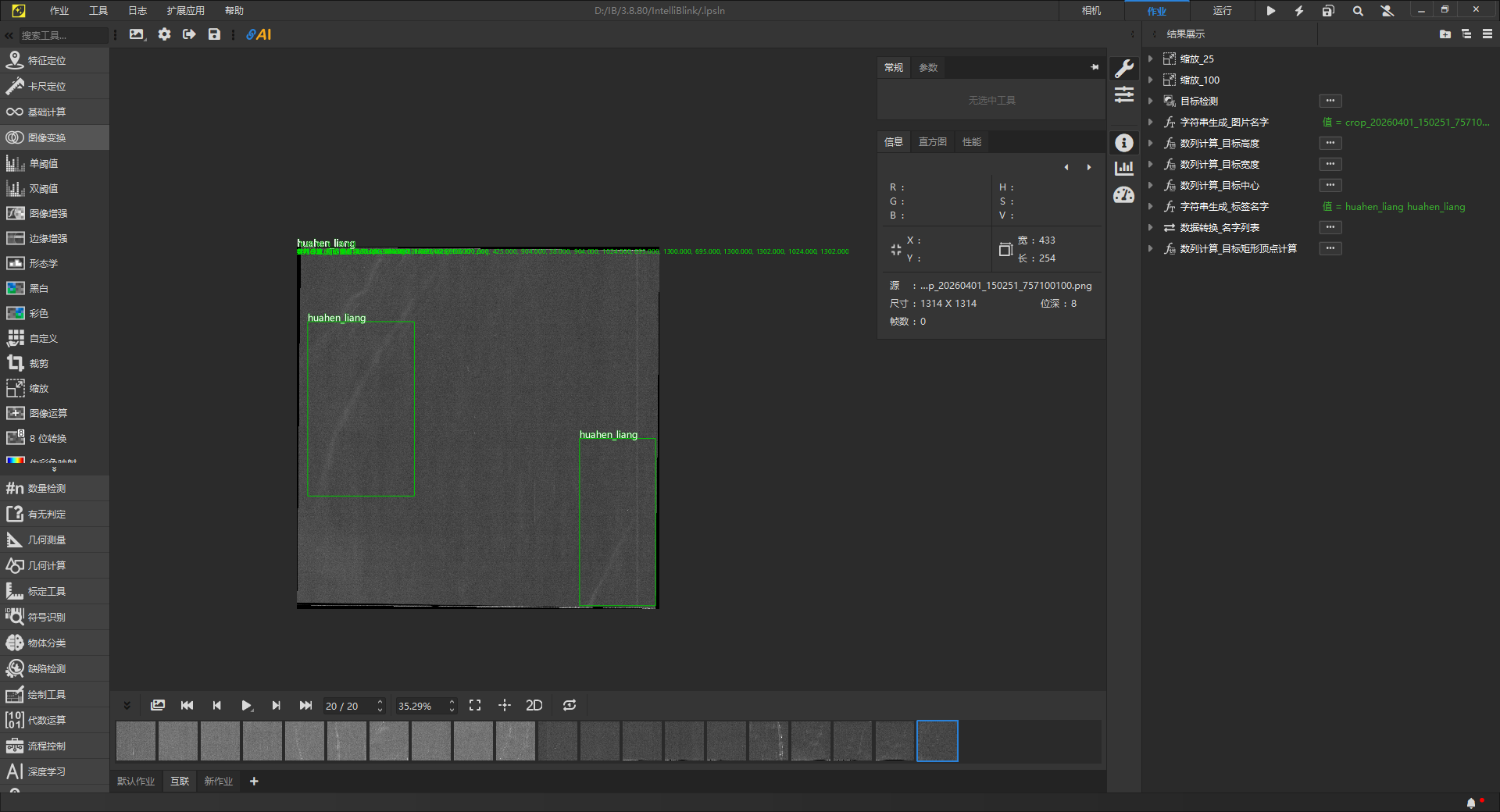
利用AI互联工具将待标签样本同步到山君。接下来用个最小案例大概展示一下如何使用。
在模型训练的前期准备阶段,通常需要采集大量缺陷样本。然而在实际工业视觉场景中,相机视野往往存在冗余背景。为了保证训练效率,通常需要对图像进行裁剪,以获得尺寸更小、特征更集中的 ROI(感兴趣区域)图像。
-
图像缩放 → 特征定位 → ROI 区域提取 → 仿射变换矫正 → AI互联同步
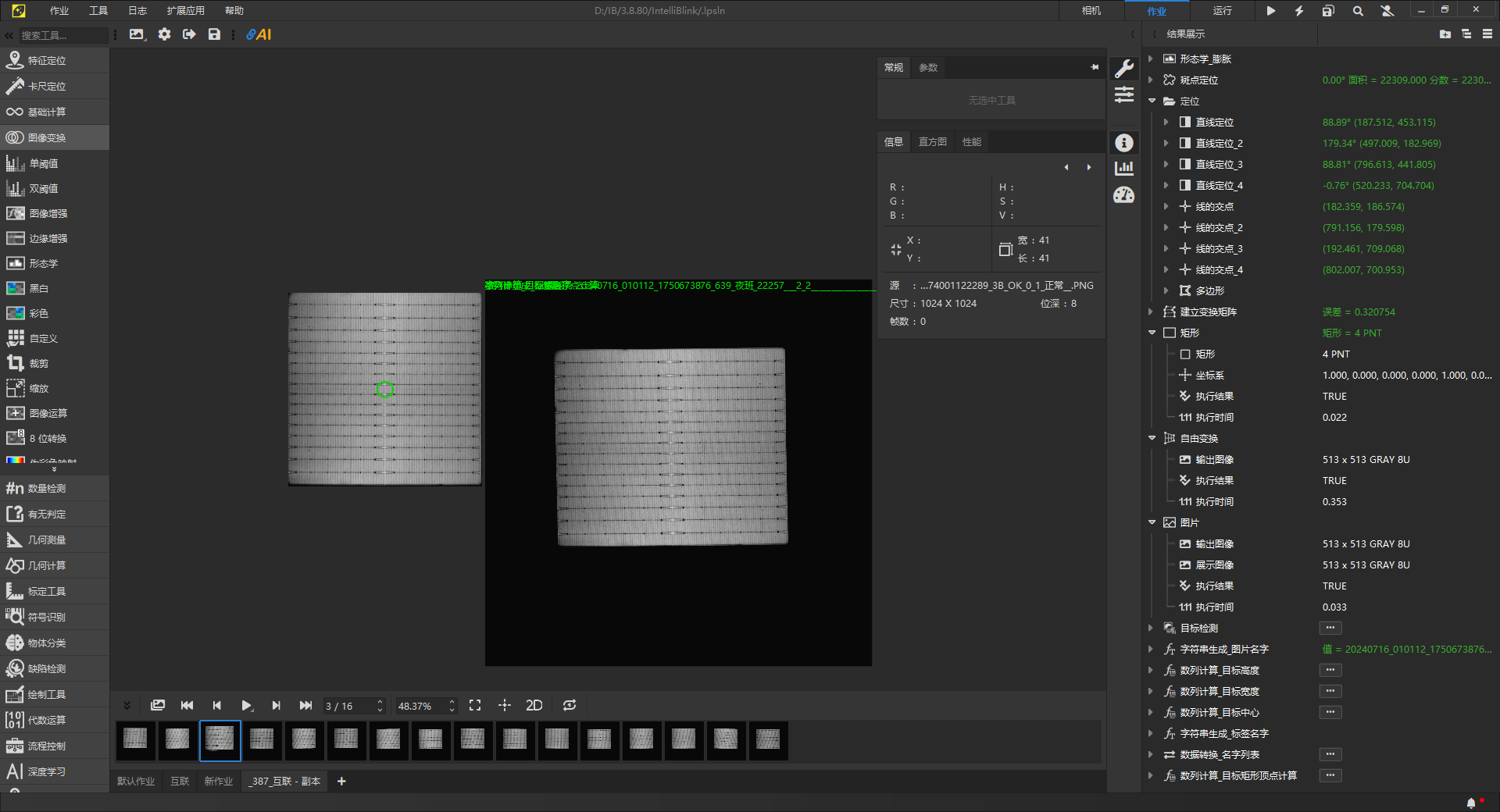
在测试案例中,通过定位+仿射变换以精确得到ROI -
互联工具导出样本使用
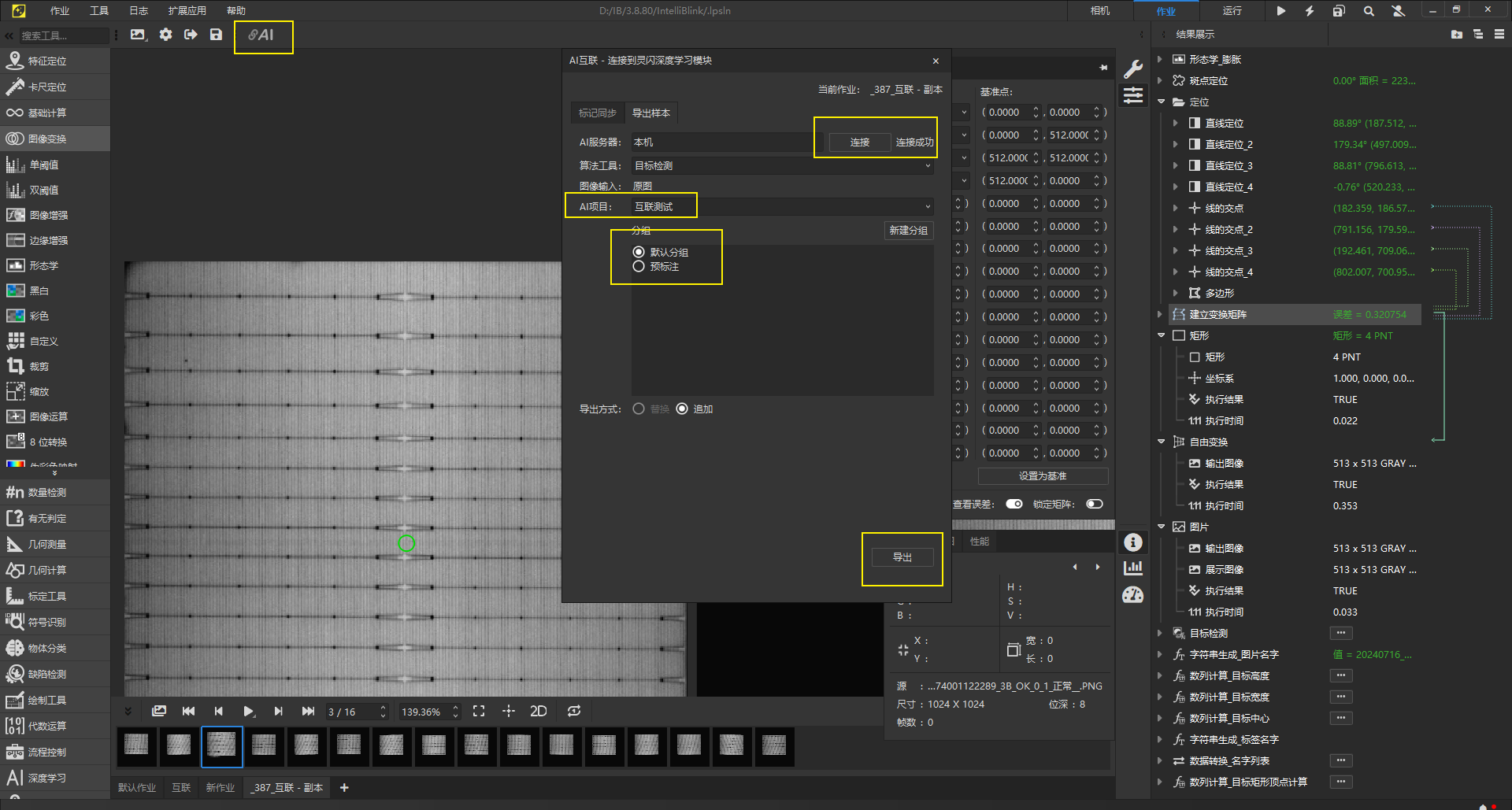
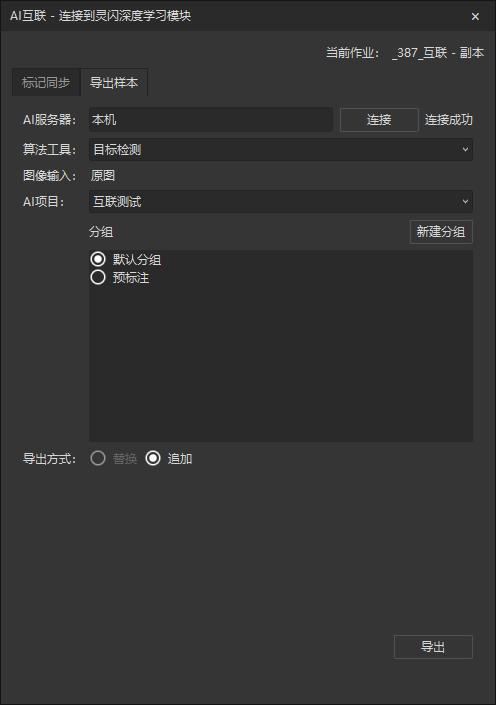
在AI互联工具中、连接本机、选择对应项目、导出
山君刷新,即可将缺陷样本直接同步至山君
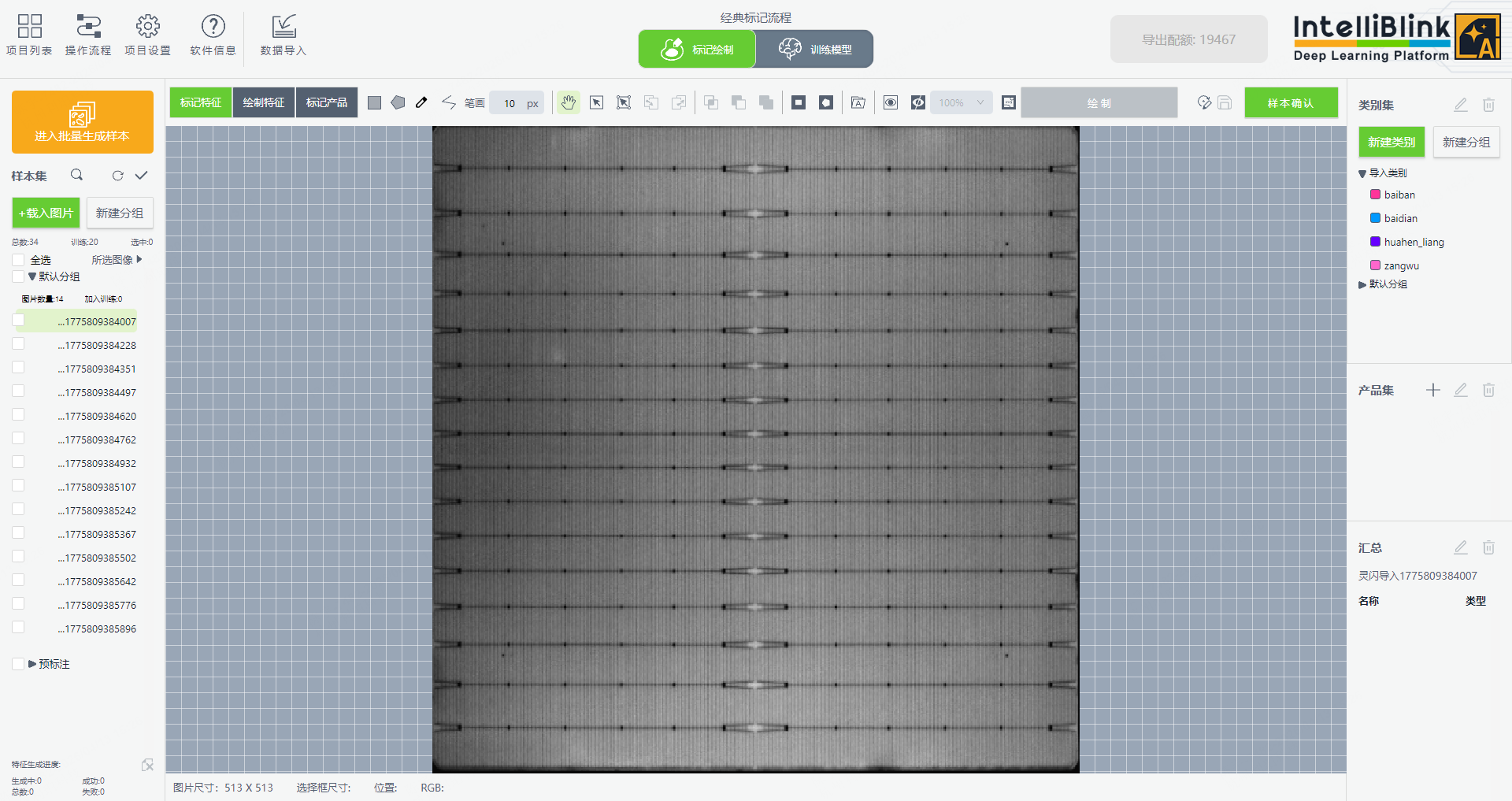
预期使用场景
在模型迭代优化过程中,尤其针对圆柱形的样品,目标检测的来源图往往是多个2D相机拍摄组成的,这里会引入一个问题:缺陷样本数量很多、模型很多、迭代优化引入的漏检样本比较多。
对于迭代优化的模型,漏检样本中往往存在模型已经能够准确检测的其他缺陷,若需要将此样本增加到模型中训练需要将整张样本的所有缺陷标记,对于上文提到的多种视角拍摄的图片会出现重复工作量较大。
因此,基于已有模型的预标注功能能够降低重复工作量,对于漏检图片已有模型可以将存在缺陷标记、模型迭代优化人员只是判别检测框是否正确。
目前可行的解决方案是,利用灵闪目标检测工具+输出适配器+外部脚本构造json文件的方式实现预标注功能。
- 测试案例
我们需要将已有的缺陷模型标记通过适配器加脚本的方式给出,首先我们要确认一下labelme的缺陷标记json文件格式。
举个例子,下面是一个json文件格式,由此可知我们需要输出 标签名字、多边形标记框的顶点、图片名字、图片高度、图片宽度
{
"version": "5.2.1",
"flags": {},
"shapes": [
{
"label": "cat",
"points": [
[120.5, 150.2],
[220.8, 160.7],
[210.3, 280.4],
[130.6, 270.9]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "image_001.jpg",
"imageData": null,
"imageHeight": 480,
"imageWidth": 640
}
那么我们需要在灵闪中配置输出参数代理。首先构造目标中心、目标高度、目标宽度,在灵闪内计算。具体步骤不在赘述。
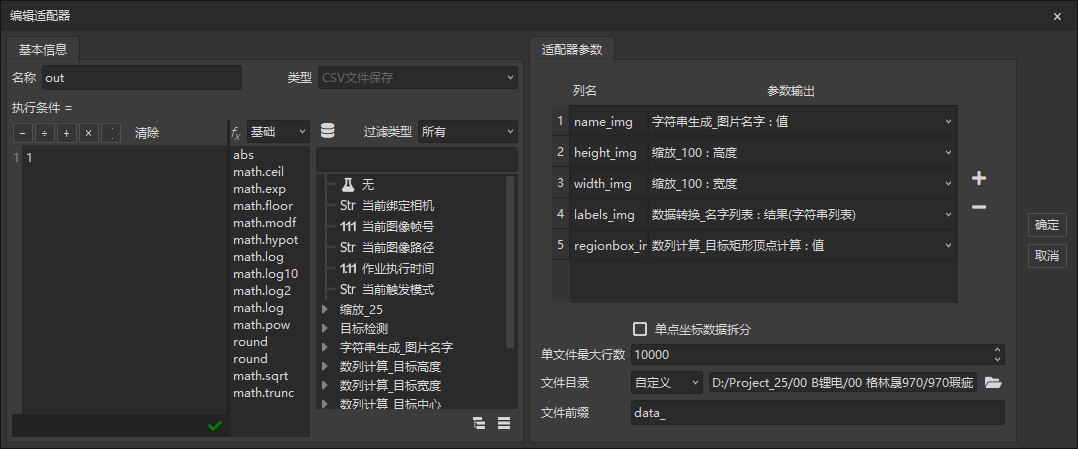
通过灵闪输出适配器,我们可以得到一个针对单张图的图片名字、图片宽高、当前图片标签列表、当前图片标签对应的box框顶点。
接下来,我们需要一个python脚本来解析csv并将其生成一个json文件。我们利用ai来帮我们生成一下解析代码。
import pandas as pd
import json
import os
from typing import List, Dict, Any
import numpy as np
def parse_csv_to_labelme(csv_path: str, output_dir: str = "labelme_annotations"):
"""
解析 CSV 文件并生成 LabelMe 格式的 JSON 文件
Args:
csv_path: CSV 文件路径
output_dir: 输出 JSON 文件的目录
"""
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 读取 CSV 文件
# 注意:您的 CSV 有 BOM 字符(开头是 ),所以用 utf-8-sig
df = pd.read_csv(csv_path, encoding='utf-8-sig')
# 打印列名,确认结构
print("CSV 列名:", df.columns.tolist())
print(f"找到 {len(df)} 行数据")
# 处理每一行
for index, row in df.iterrows():
try:
# 提取基本信息
image_name = row['name_img']
image_height = int(row['height_img'])
image_width = int(row['width_img'])
# 处理 labels(用分号分隔)
labels_str = str(row['labels_img'])
labels = [label.strip() for label in labels_str.split(';') if label.strip()]
# 处理 regionbox_img(边界框坐标)
# 注意:regionbox_img 是一个长的字符串,包含所有框的所有坐标
regionbox_str = str(row['regionbox_img'])
# 按分号拆分得到所有数值
all_coords = regionbox_str.split(';')
# 验证数据
# 每个框有 8 个坐标(4 个顶点 * 2 个坐标)
if len(all_coords) % 8 != 0:
print(f"警告: 第 {index+1} 行坐标数量 {len(all_coords)} 不是 8 的倍数")
continue
num_boxes = len(all_coords) // 8
if len(labels) != num_boxes:
print(f"警告: 第 {index+1} 行标签数量({len(labels)})与边界框数量({num_boxes})不匹配")
continue
# 解析每个边界框
shapes = []
for i in range(num_boxes):
# 获取第 i 个框的 8 个坐标
start_idx = i * 8
end_idx = start_idx + 8
box_coords_str = all_coords[start_idx:end_idx]
# 转换为浮点数
try:
box_coords = [float(coord) for coord in box_coords_str]
except ValueError as e:
print(f"警告: 第 {index+1} 行第 {i+1} 个边界框坐标转换失败: {e}")
continue
if len(box_coords) != 8:
print(f"警告: 第 {index+1} 行第 {i+1} 个边界框坐标数量异常: {len(box_coords)} 个")
continue
# 转换为 LabelMe 格式的 points(顺时针顺序)
# 假设坐标已经是顺时针顺序:x1,y1,x2,y2,x3,y3,x4,y4
points = [
[box_coords[0], box_coords[1]], # 点1
[box_coords[2], box_coords[3]], # 点2
[box_coords[4], box_coords[5]], # 点3
[box_coords[6], box_coords[7]] # 点4
]
# 创建 shape 对象
shape = {
"label": labels[i] if i < len(labels) else f"label_{i}",
"points": points,
"group_id": None,
"shape_type": "polygon",
"flags": {}
}
shapes.append(shape)
if not shapes:
print(f"警告: 第 {index+1} 行没有有效的边界框")
continue
# 构建 LabelMe JSON 结构
labelme_data = {
"version": "5.2.1",
"flags": {},
"shapes": shapes,
"imagePath": image_name,
"imageData": None, # 用 None 代替实际图片数据
"imageHeight": image_height,
"imageWidth": image_width
}
# 生成 JSON 文件名(与图片名相同,扩展名为 .json)
json_name = os.path.splitext(image_name)[0] + '.json'
json_path = os.path.join(output_dir, json_name)
# 保存 JSON 文件
with open(json_path, 'w', encoding='utf-8') as f:
json.dump(labelme_data, f, indent=2, ensure_ascii=False)
print(f"已生成: {json_path} ({len(shapes)} 个标注)")
except Exception as e:
print(f"处理第 {index+1} 行时出错: {str(e)}")
import traceback
traceback.print_exc()
continue
def main():
# 使用示例
csv_file = "data_1990751777.csv" # 您的 CSV 文件名
output_dir = "labelme_json_files" # 输出目录
# 解析并生成 JSON
parse_csv_to_labelme(csv_file, output_dir)
print("\n处理完成!")
print(f"JSON 文件保存在: {output_dir}/")
if __name__ == "__main__":
main()
山君加载文件
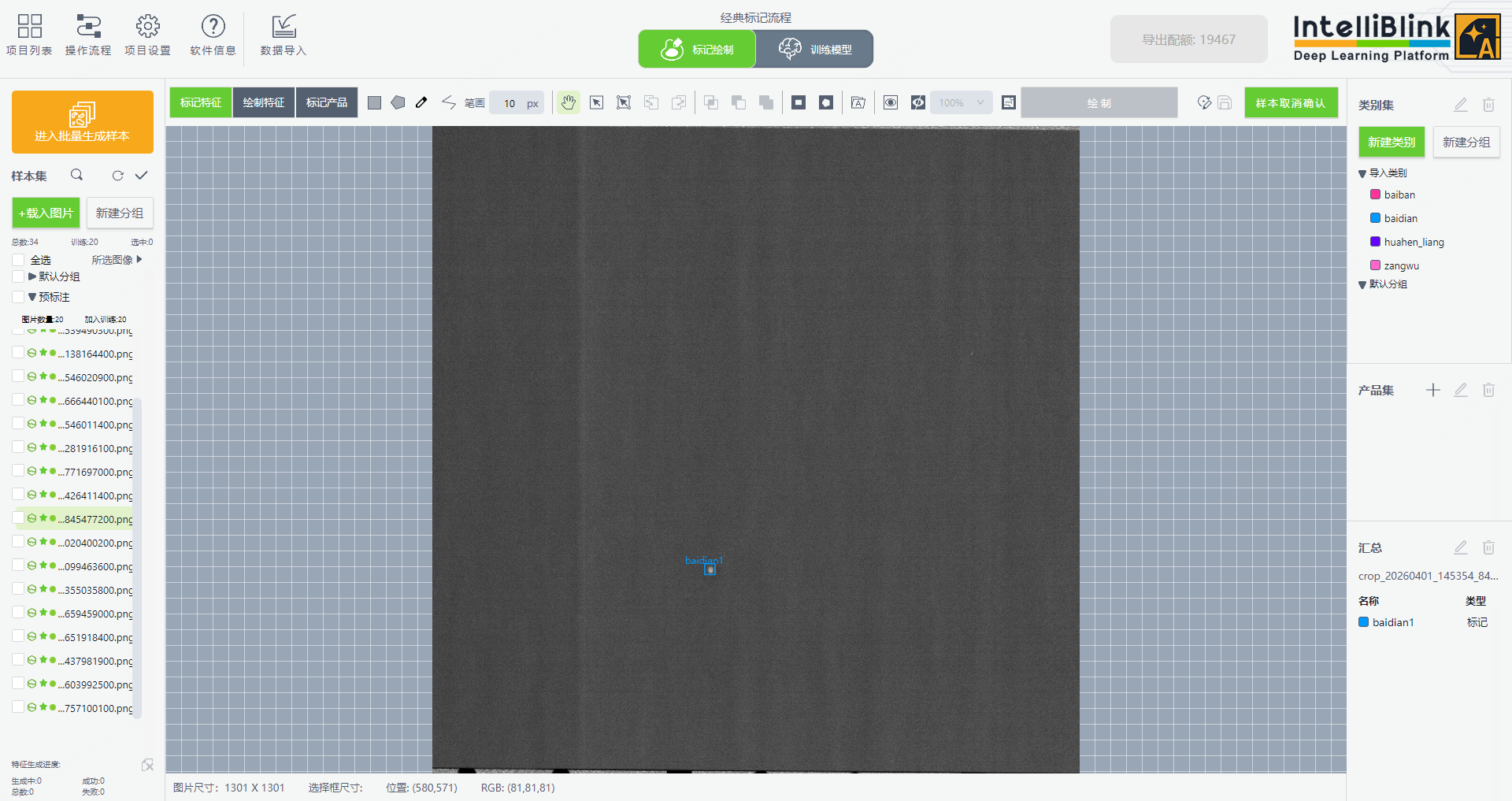
当然,Labelme 原生支持将图片转为 Base64 存入 imageData ,在山君加载labelme格式的图片和标签很可能是分开加载的,即山君加载labelme格式样本imageData可以为null,故输出适配器没有配置相关字段,若后续需要在labelme上操作可以配置相关Base64输出或者用山君导出一遍labelme格式即可。
综上,我们实现了利用已有模型来进行预标注的功能,此举可以减少模型某些重复且精确的标签,人工只需要复核标签或增加新的漏检标签。