
如题
1 Answers
做机器视觉的软件(算法)开发,最常操作的对象就是图像。
虽然各种成熟的库提供了非常多高级图像接口,大多数情况下,大家可能不需要关心像素怎么取存。
但是,作为一个有追求的机器视觉工程师,你还是得有手撸图像算法的能力。
否则,你调的库的能力上限,就是你的能力上限。
而手撸图像算法,通常意味着你得找到图像中你关心的像素,进行各种运算。
所以,像素在内存中怎么存,就变成了一个重要的问题。
你可能会不加思索地说:“这有什么难的?不就是根据像素的(x, y)坐标,调接口去拿像素值就行了吗?”
我面试的时候,经常会问一个问题:给定一个3通道8位RGB彩色图,我想通过直接修改像素值的方法,让这个图变亮或变暗,所以,用最容易想到的方法,我写了两层for循环遍历x和y的坐标,代码(部分接口大家当伪码看就好)如下
for(int x = 0; x < width; ++x)
{
for(int y = 0; y < height; ++y)
{
unsigned char r, g, b;
get_pixel_value(x, y, &r, &g, &b);
set_pixel_value(x, y, r + 10, g + 10, b + 10); // 想变亮就+,变暗就-
}
}
如果我把这份代码的两层for循环对调一下顺序,改成下面这样
for(int y = 0; y < height; ++y)
{
for(int x = 0; x < width; ++x)
{
unsigned char r, g, b;
get_pixel_value(x, y, &r, &g, &b);
set_pixel_value(x, y, r + 10, g + 10, b + 10); // 想变亮就+,变暗就-
}
}
两段代码的结果完全一致,请问:哪段代码运行耗时更少?为什么?
要准确回答这个问题,还是得从像素在内存里怎么存开始。
虽然存的方法有很多种,但,通过总结我们常用的各种开源或闭源的能够处理图像的软件,其实只有三种:
- 行优先通道交错存储;
- 列优先通道独立存储;
- 行优先通道独立存储。
看起来是不是不知所云?没事,我们先来看一下下面这个小动画
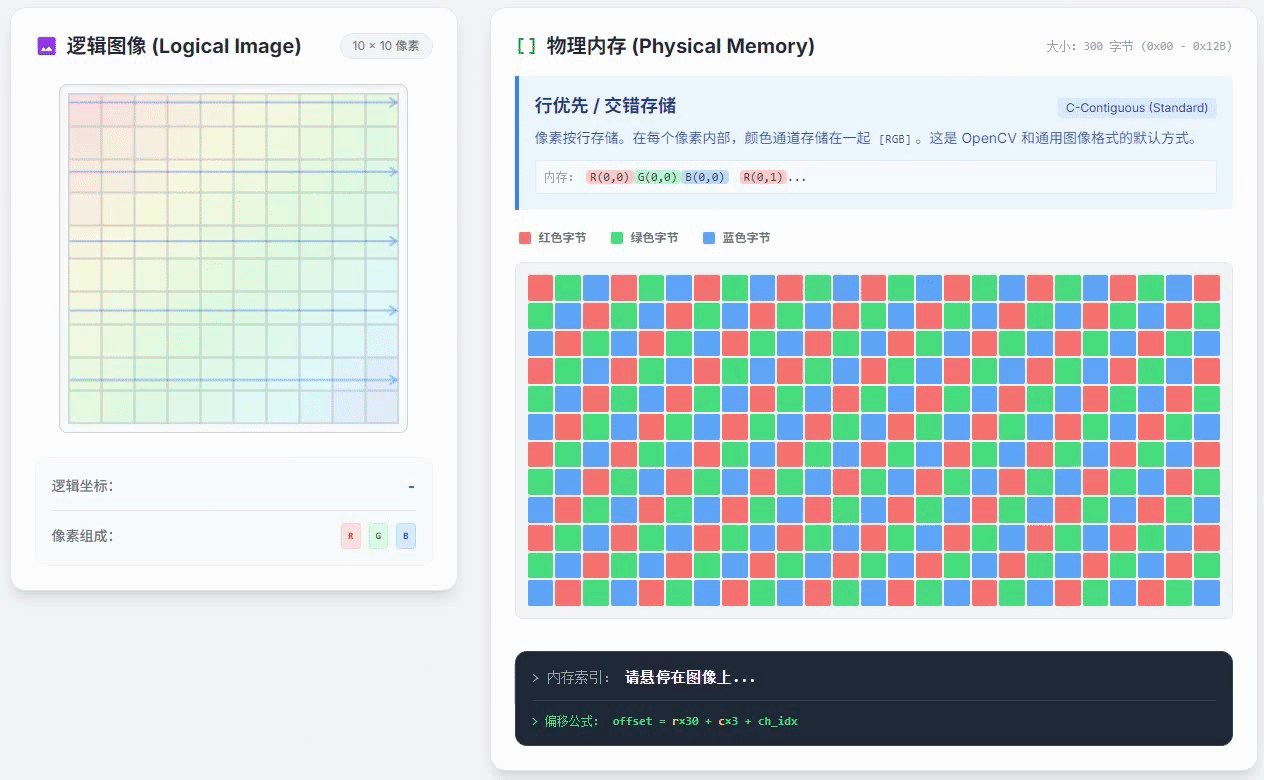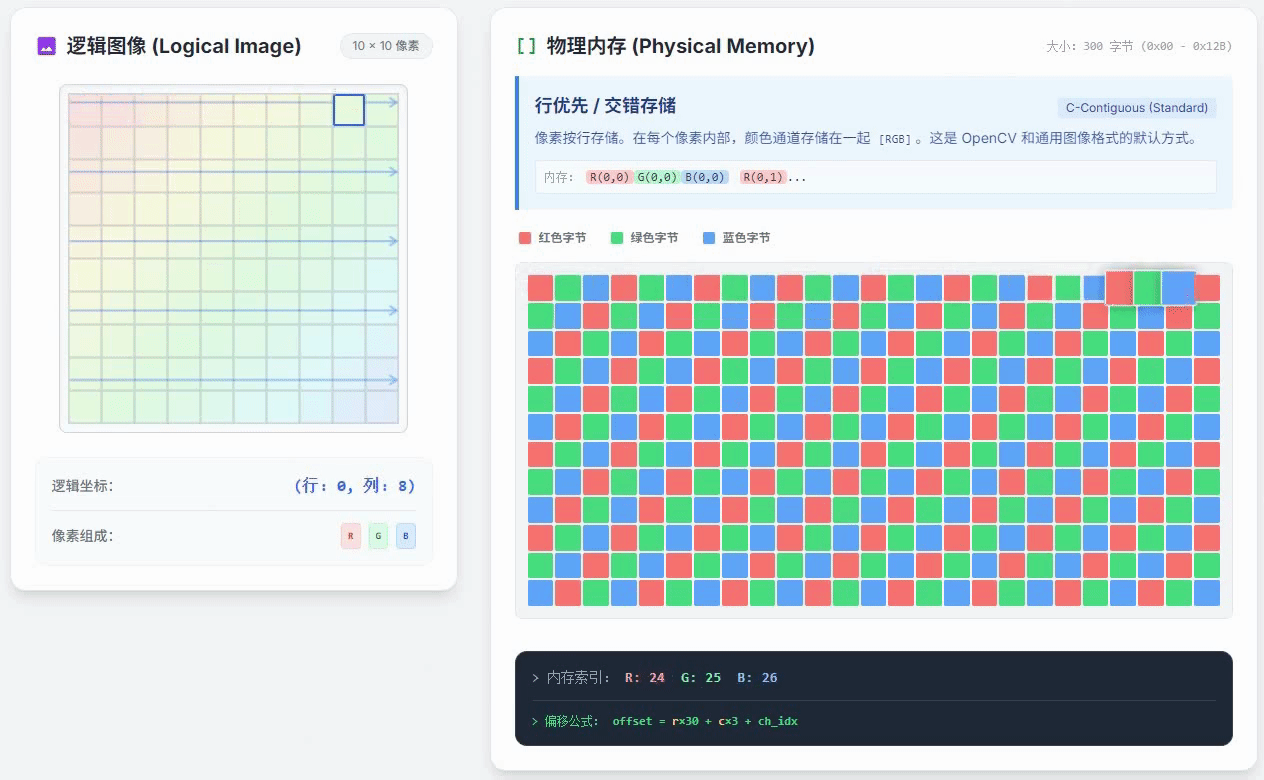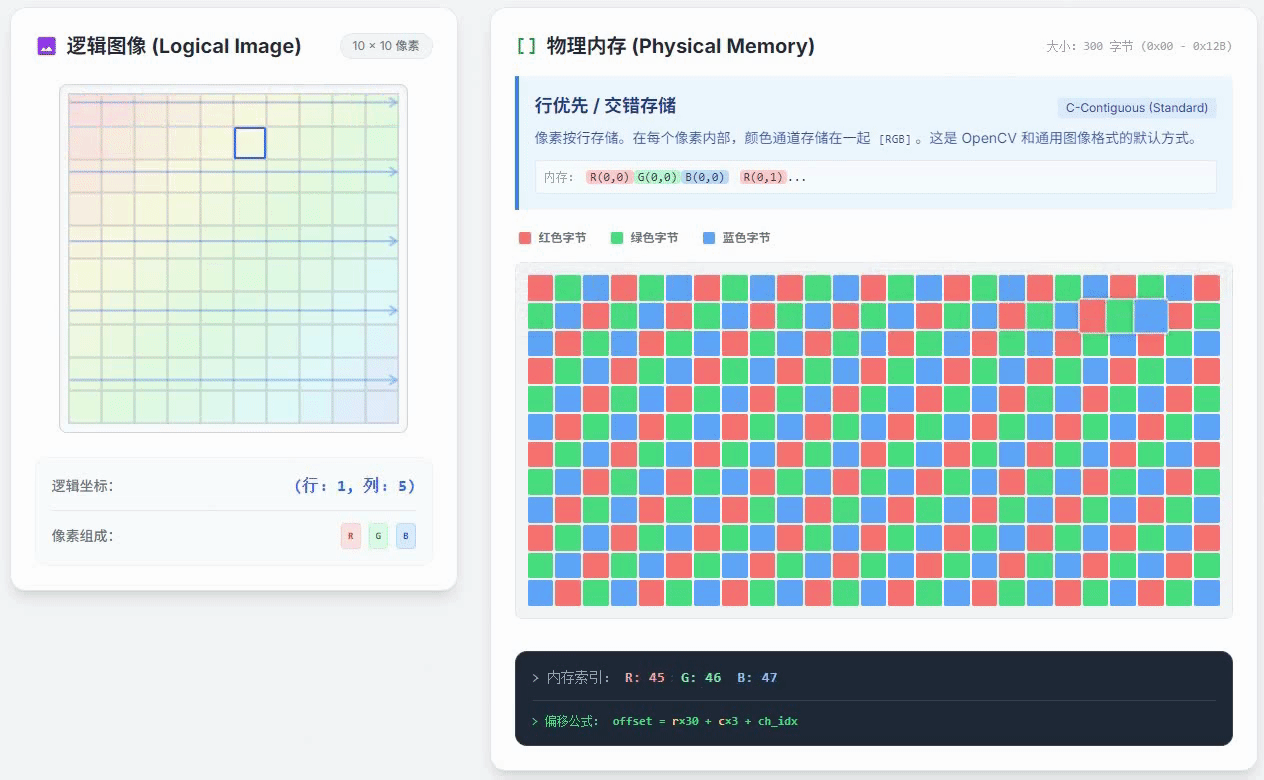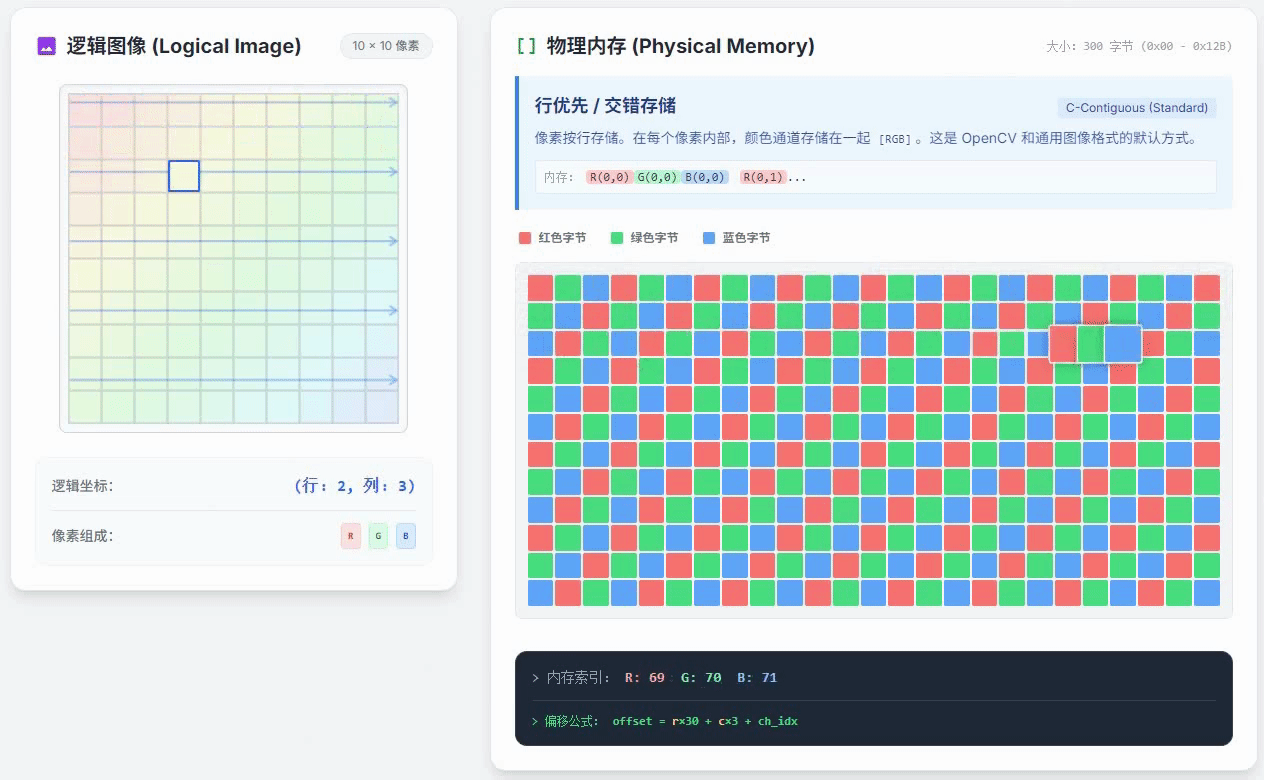
上面这个动画里放的就是行优先通道交错存储,这是一种最常见的存储方式,比如OpenCV里面的cv::Mat中存储的像素数据就是采用这种方式来存储的。从这个动画里不难看出通道交错和行优先的含义:
通道交错:每个像素的RGB三通道颜色数值是紧密存储的,R像素之后紧挨着G像素,G像素之后紧挨着B像素,这样存好之后,总体上看,就会感觉三种颜色的通道是交错的;
行优先:优先把属于同一行的像素数据紧挨着存好,再开始存下一行的数据,这就是行优先的意思。
于是乎,聪明如你一定也能想到,既然有行优先,就一定会有列优先,既然有通道交错,就一定会有不交错,我称之为通道独立,因为此时每个通道的数据都是独立存在一份连续的内存空间里,不参杂别的通道数据在一起。
列优先通道独立存储的小动画如下
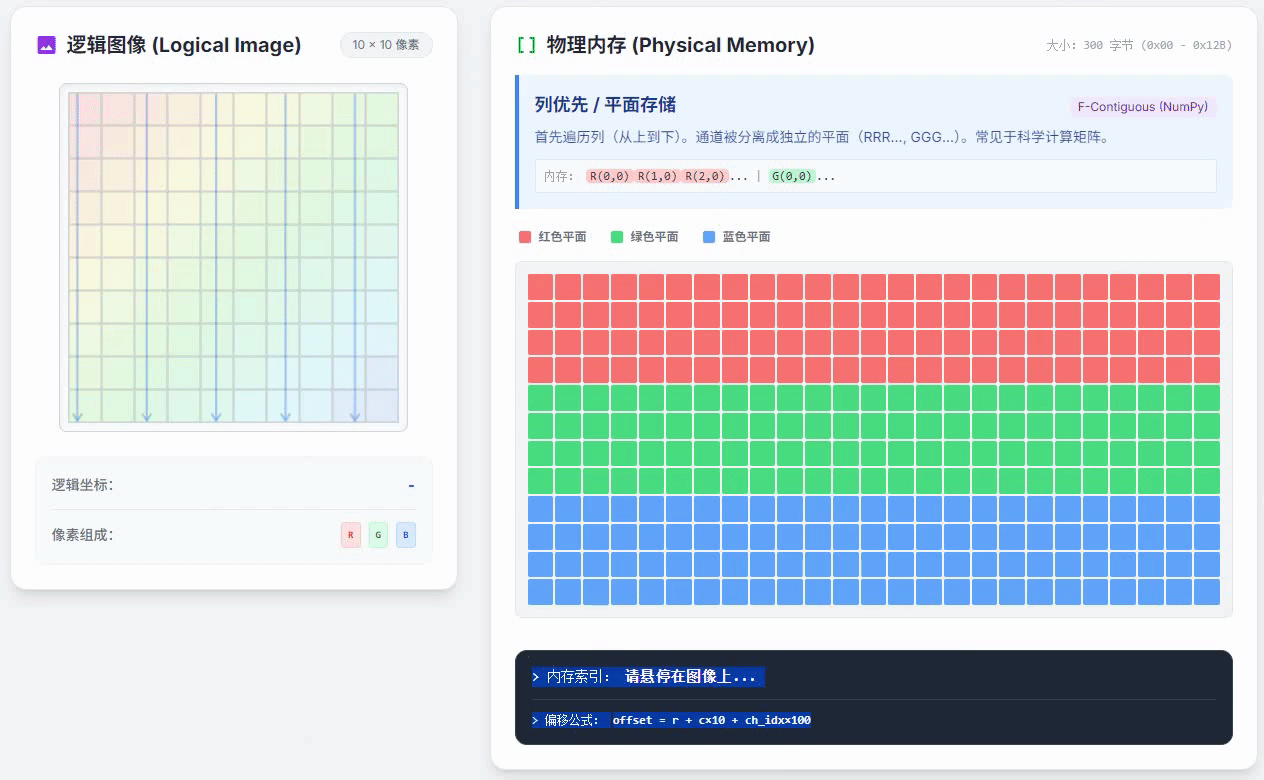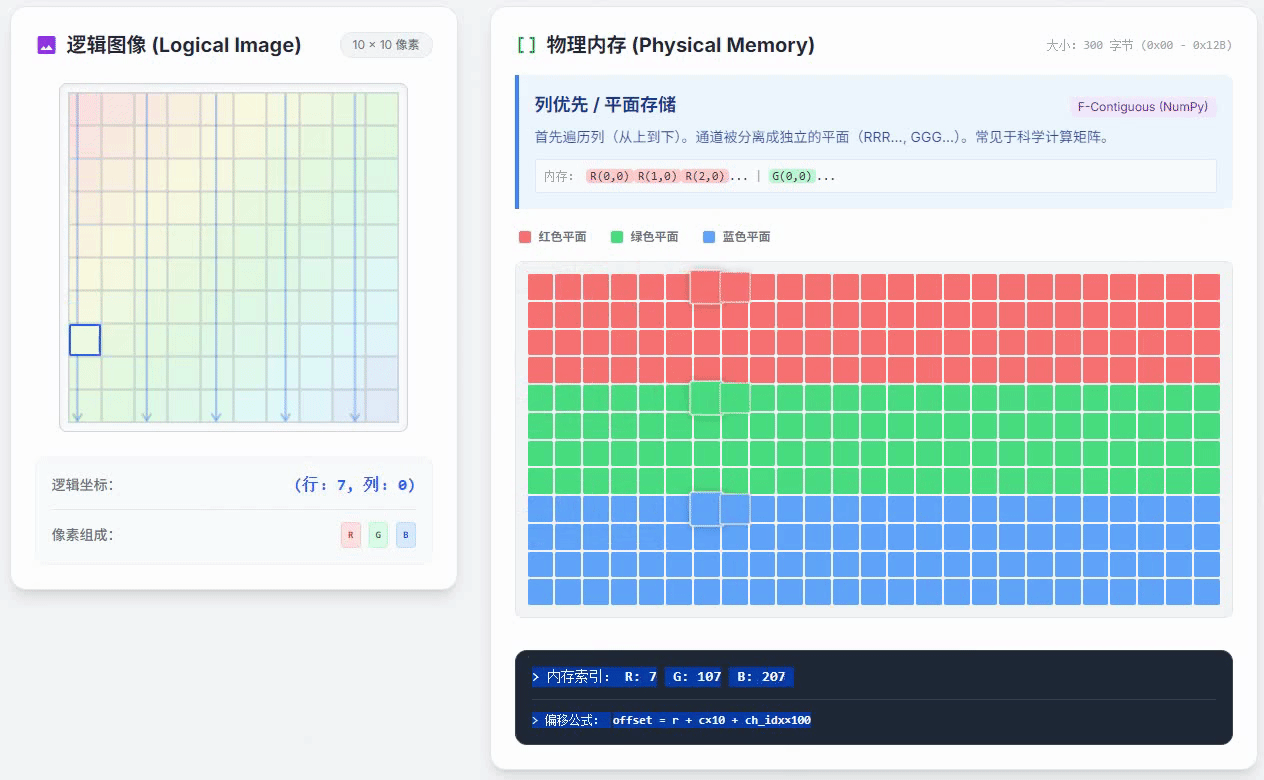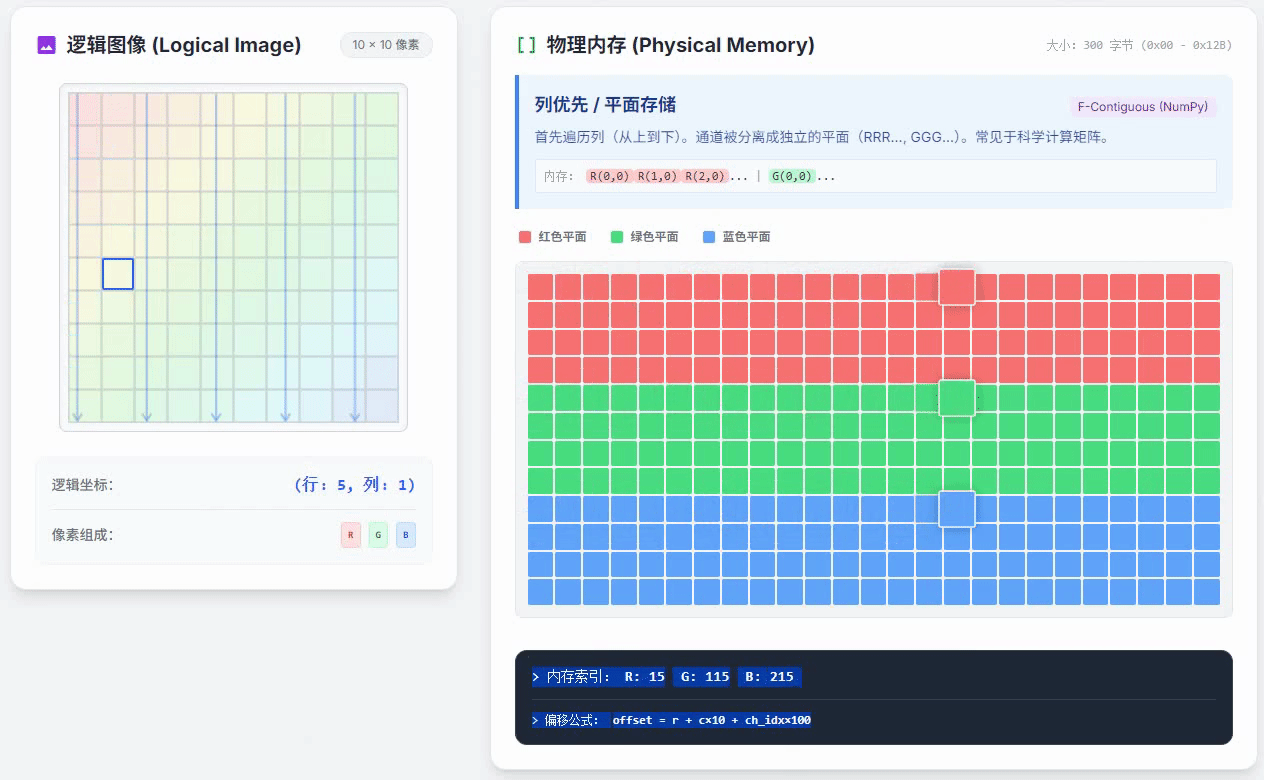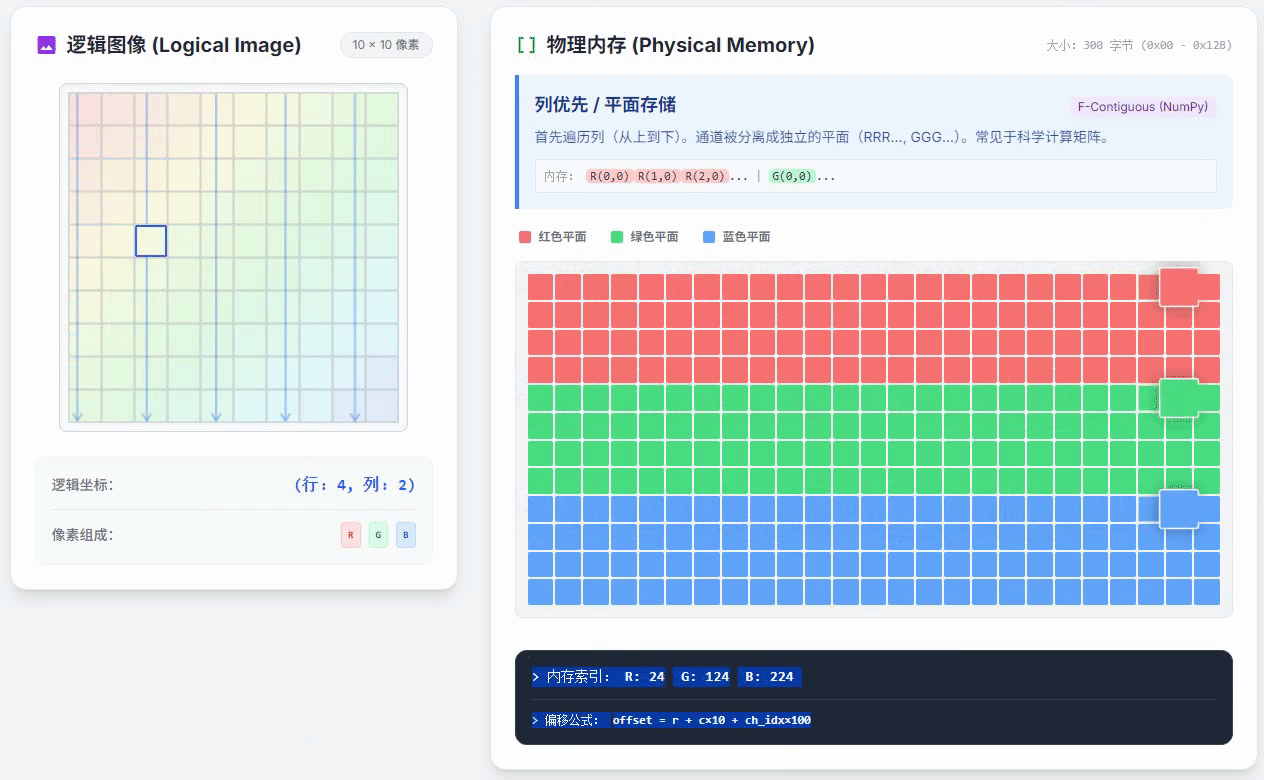
这种方式的特点是,RGB颜色数值是完全分开,先把R平面的所有数据都存好,再存下一种颜色的数据。在一个颜色通道内,按照列优先的方式存储。
行优先通道独立存储的小动画如下
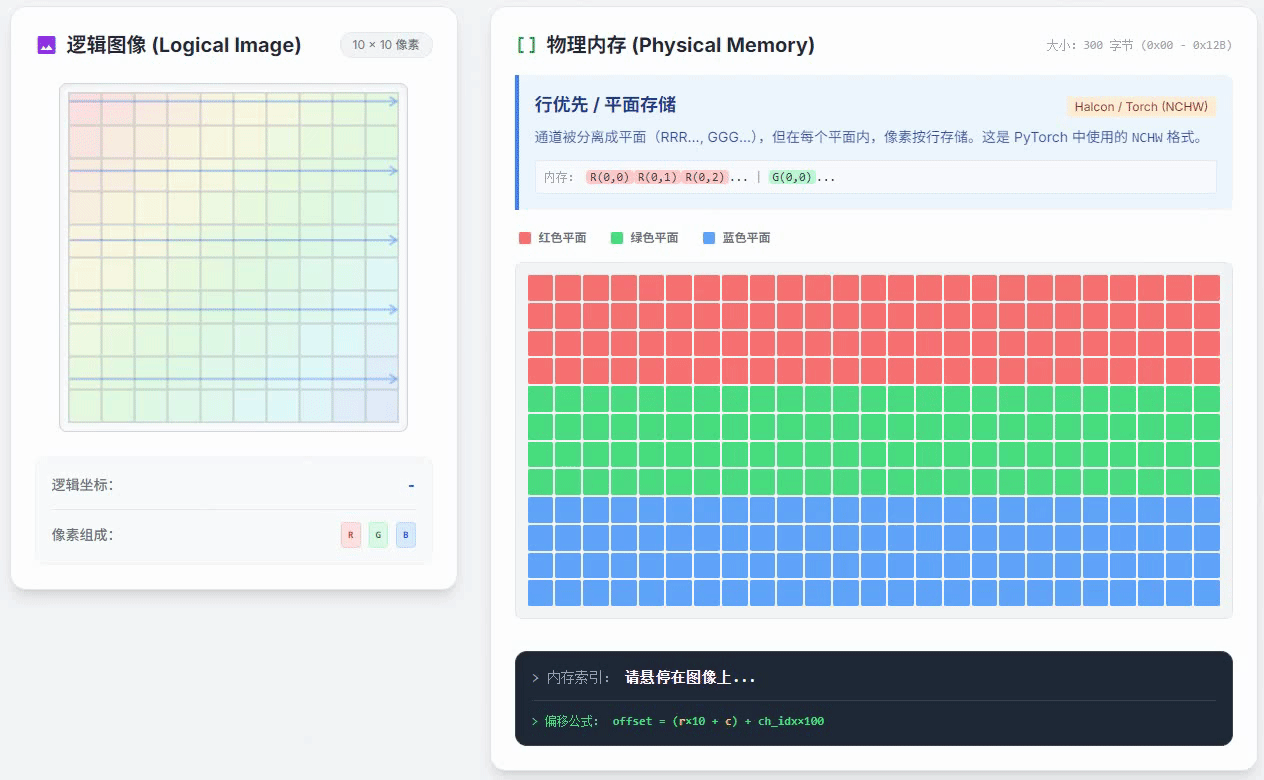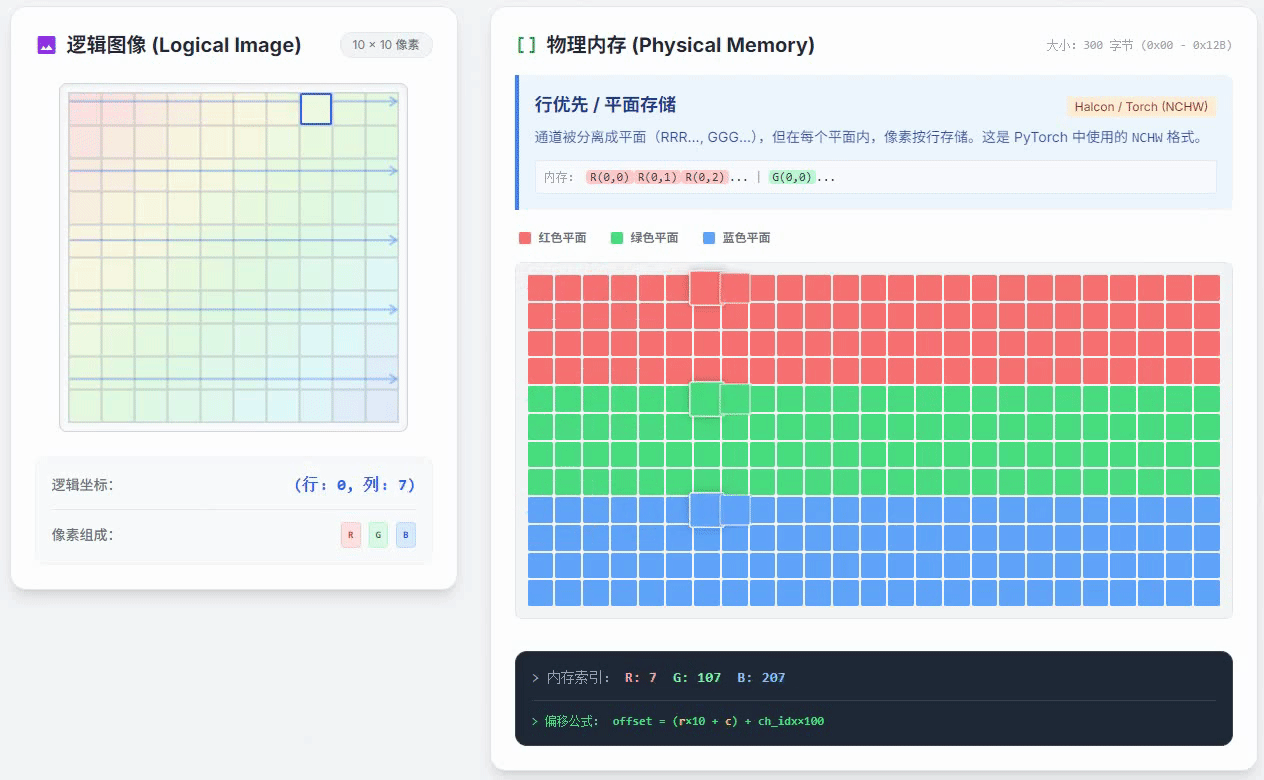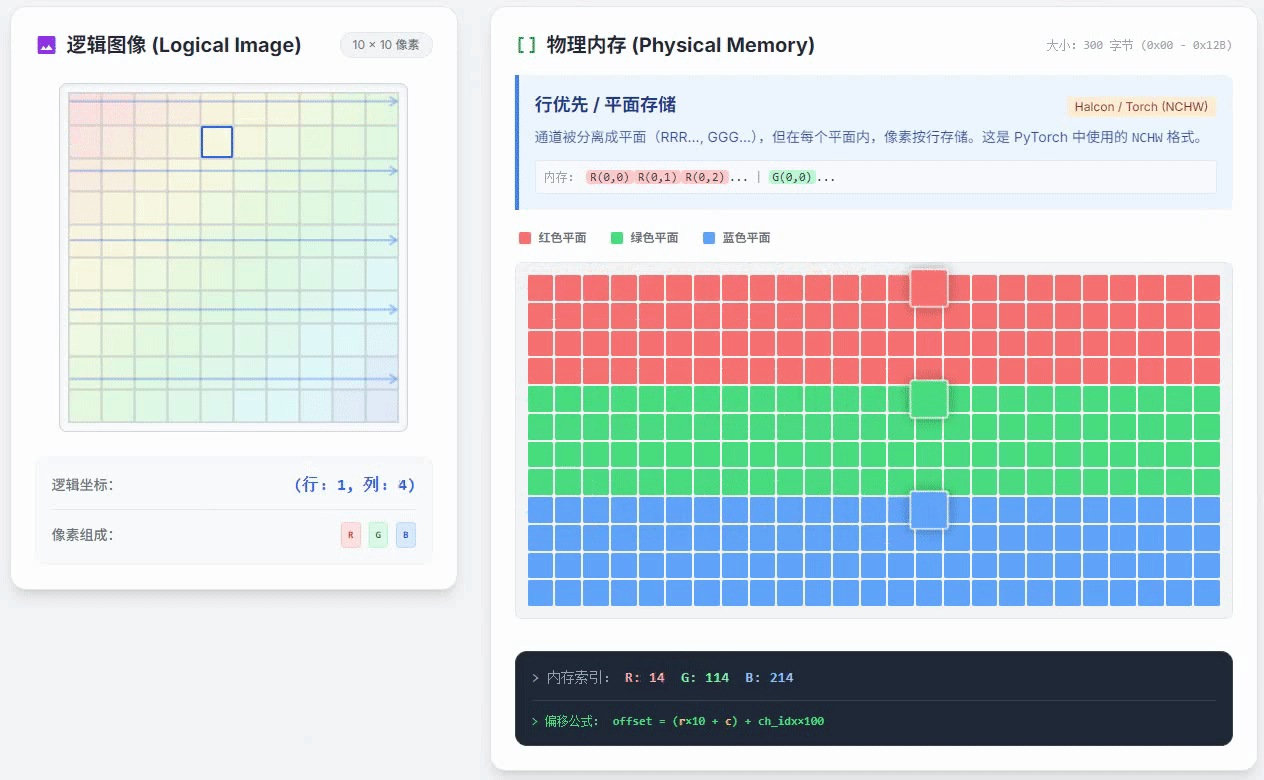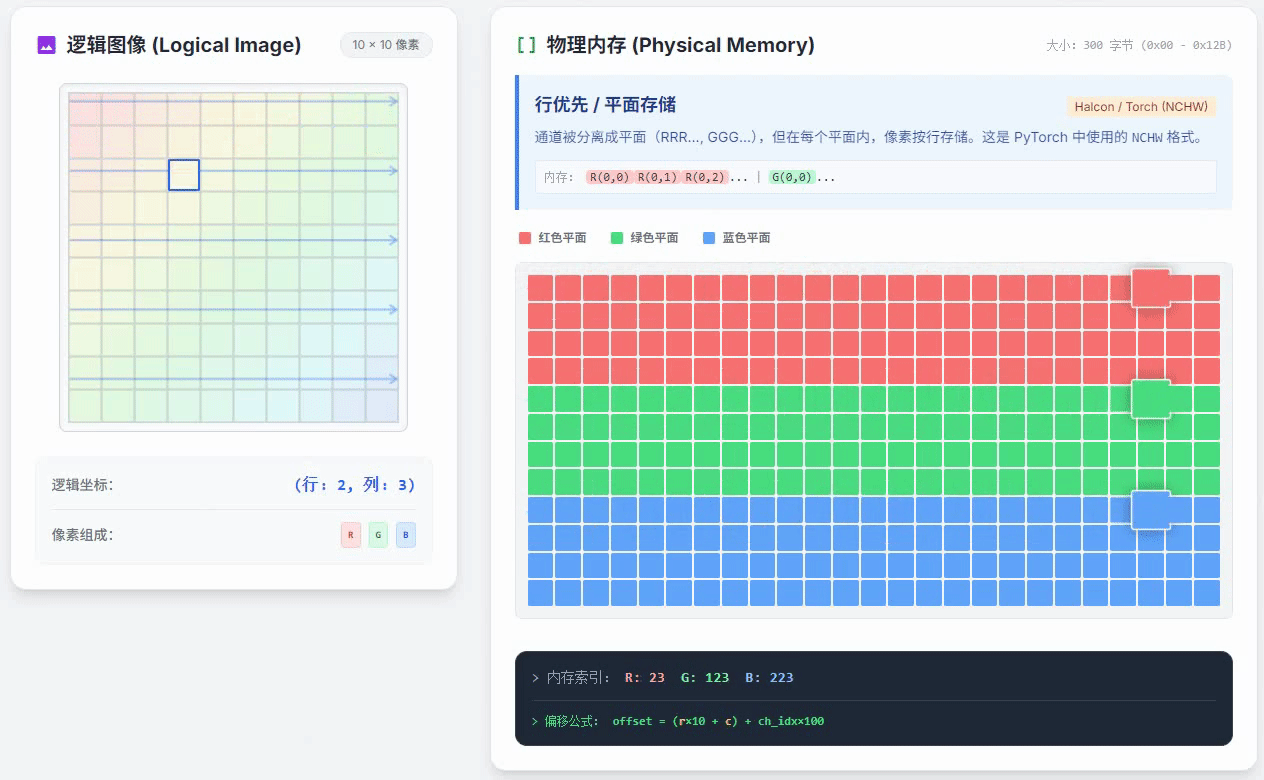
这种方式和列优先通道独立存储唯一的区别就是,在一个颜色通道内,按照行优先的方式存储。
上面三种方式描述了像素在内存里的主要存储方式,但实际上,还有一些细节需要补充。
比如为了加速图像数据在CPU上的处理速度,需要让待处理的数据的字节数尽量是4的倍数:
为了达到这个目的,有些软件使用行优先的存储方式时,会对每行数据进行4字节对齐的处理,就是说,如果一行的总字节数不是4的倍数,则在行末补上几个字节,使其能被4整除;
也有软件会对每个像素的数据都进行4字节对齐处理,这时,如果是3通道且每个通道是8位的情况,每个像素的第4个字节就可能是为了对齐而插入的空字节。
再比如,通道独立存储的方式中,有些软件设计数据结构时,会单独存储每个颜色平面的数据指针,以方便快速获取某一个颜色通道的数据。
说了这么多听起来像是“回字的十种写法”一样的内容,究竟有什么意义呢?意义大了。
现在我们可以回到最开始的那两段代码了。我们先看第一段代码
for(int x = 0; x < width; ++x)
{
for(int y = 0; y < height; ++y)
{
unsigned char r, g, b;
get_pixel_value(x, y, &r, &g, &b);
set_pixel_value(x, y, r + 10, g + 10, b + 10); // 想变亮就+,变暗就-
}
}
如果,现在图像的像素是行优先通道交错存储的,上面这段代码运行时访问内存的过程,就和下面这个动画展示的一样
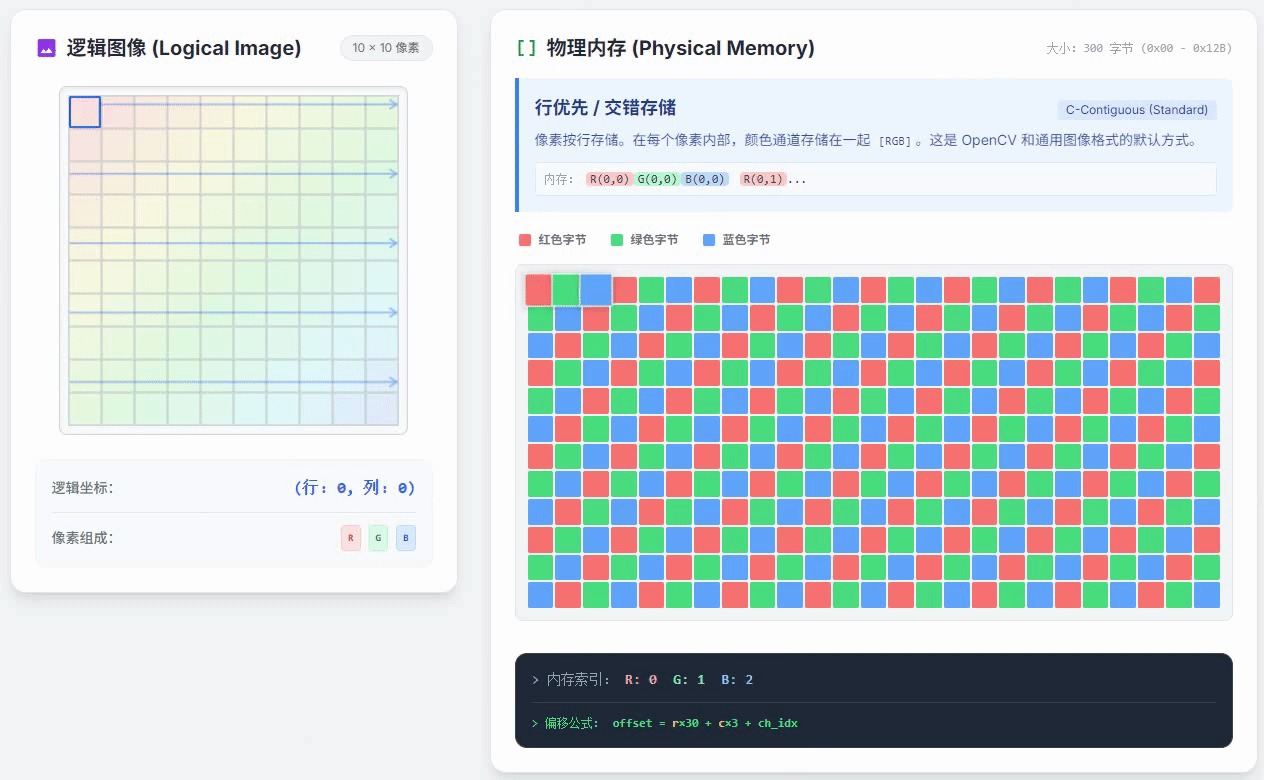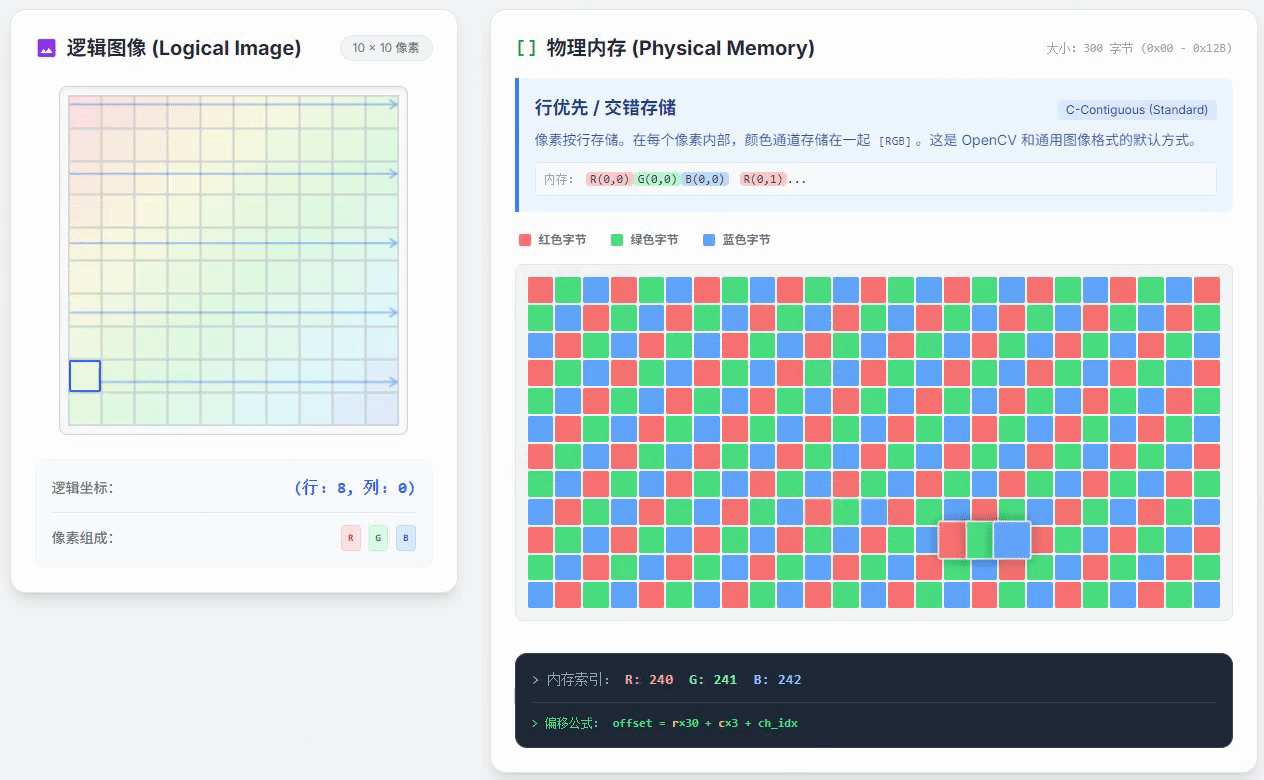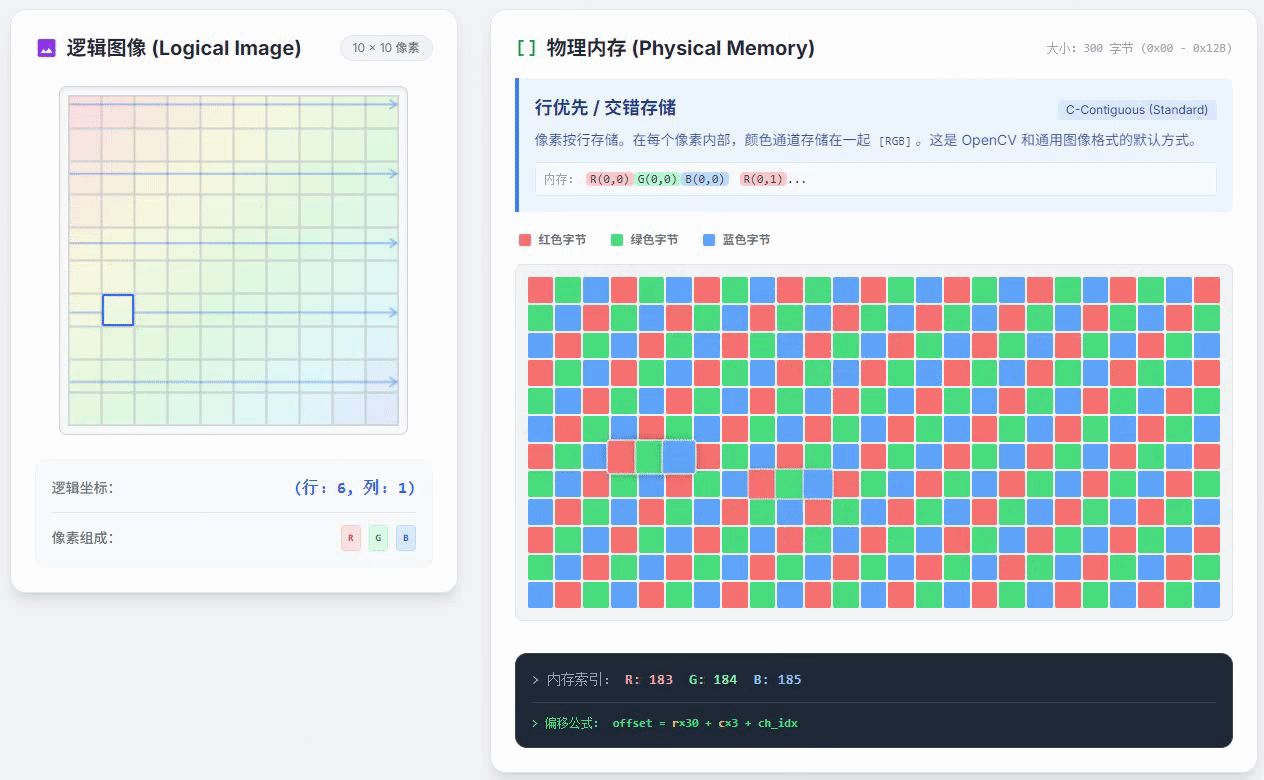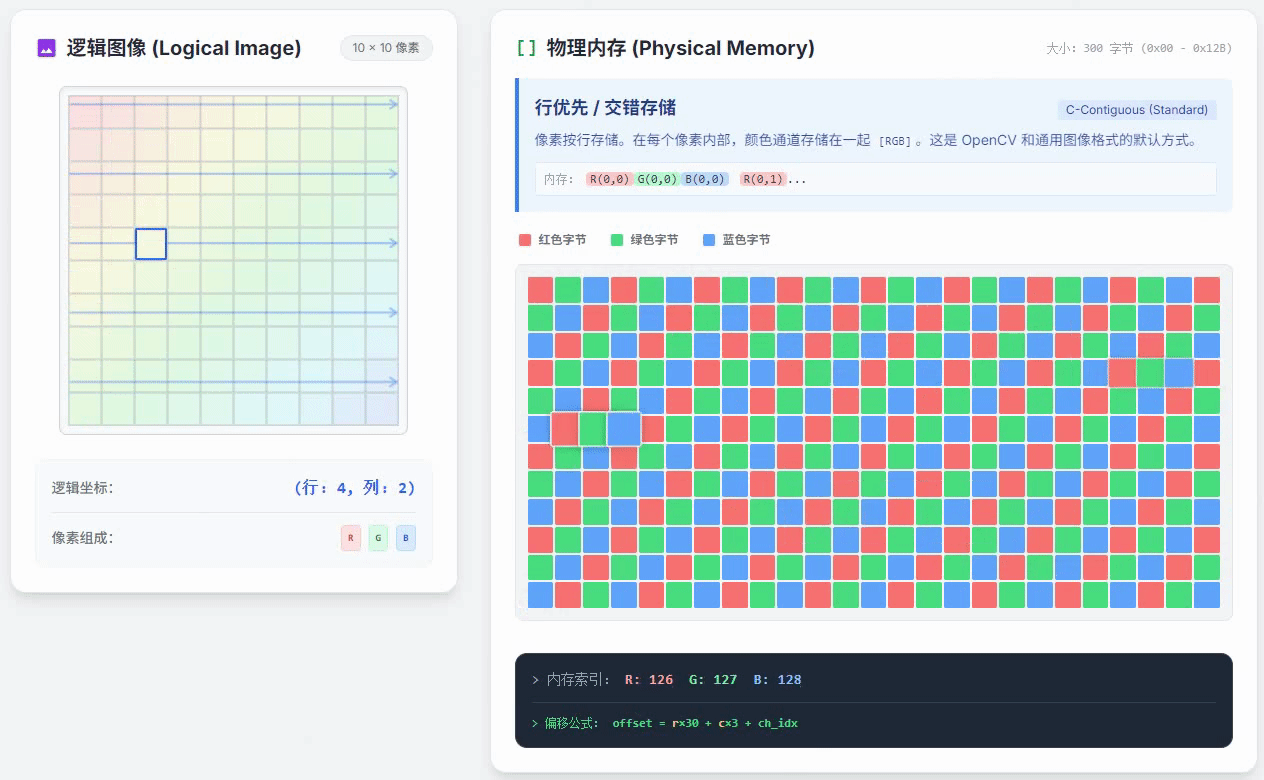
从这个动画中可以明显看出,逻辑图像上的像素是在列优先逐个像素遍历的,但是右侧的物理内存里看到的对应像素的位置却一直在跳变。这种情况会让程序的运行速度变慢。
为什么?
因为现代CPU为了能够更快地将内存中的数据搬运到寄存器中来进行运算,会一次性搬运当前访问的字节附近的更多的字节到多级缓存和寄存器中,因为万一下一个要访问的字节就刚好在这一次性搬运的其它字节中的话,就可以省去很多搬运数据的时间。别以为这一点时间节省很少,因为你操作的是图像数据,它没啥别的特点,最大的特点就是数据量通常都很大,每个字节的访问如果都能节省一点时间,那总的时间节省会很可观。
工程师这么设计CPU的原因是,CPU访问的数据经常符合“局部性原理”,比如(大误):你和女朋友分手之后,大概率你女朋友会和你同寝室的哥们儿好上ヽ(`Д´)ノ。
虽然,实际上访问数据的顺序是由你的代码决定的,但搞CPU芯片和体系架构设计的那帮工程师已经提前这么设计好了,你没辙,只要你老板还要求你写的软件不能跑的跟蜗牛一样慢,或者不能放任你总是选用最贵的CPU,你只能follow符合“局部性原理”的设计原则,尽量让你的软件也能够连续访问在内存中紧密存储的数据。
好了,现在再回到上面的那两个for循环的代码上来。
所以,如果现在我们的图像是行优先紧密存储的,两层for循环就需要调换一下顺序,变成
for(int y = 0; y < height; ++y)
{
for(int x = 0; x < width; ++x)
{
unsigned char r, g, b;
get_pixel_value(x, y, &r, &g, &b);
set_pixel_value(x, y, r + 10, g + 10, b + 10); // 想变亮就+,变暗就-
}
}
这样运行速度就更快了。
那么问题又来了,如果图像现在是列优先通道独立存储,代码又当怎么写才能符合局部性原理呢?
for(int c=0; c < 3; ++c) // c表示颜色通道索引
{
for(int x = 0; x < width; ++x)
{
for(int y = 0; y < height; ++y)
{
unsigned char value;
get_pixel_value(c, x, y, &value);
set_pixel_value(c, x, y, value + 10); // 想变亮就+,变暗就-
}
}
}
总之,毛要顺着捋,每个像素的字节也要按顺序访问。行优先平面存储的情况就不再赘述了。
如果你喜欢反思,这时候很可能会有一个额外的疑问:为什么会有那么多不同的图像数据存储方式呢?
这是一个好问题!
我们先来看一下知名的图像处理有关的开源和闭源软件中的像素存储方式:
| 软件名 | 图像类名 | 像素存储方式 |
|---|---|---|
| OpenCV | cv::Mat | 行优先紧密存储 |
| Numpy | ndarray | 行优先紧密存储(常用,以np.ascontiguousarray()保证) |
| scikit-image | ndarray | 行优先紧密存储(常用,以np.ascontiguousarray()保证) |
| Torchvision | torch.Tensor | 行优先平面存储 |
| Halcon | HImage | 行优先平面存储 |
| Matlab | mxArray | 列优先平面存储 |
概括地说,不同的软件,在设计之初,都有它各自的设计目标,由此造就了各种不同的设计决策,并最终形成了很多传承下来的习惯。
行优先存储的设计,首先是和C语言的习惯类似,C语言中的二维数组在内存中就是按行存储的。这意味着二维数组 A[row][col] 中,A[0][0] 的下一个内存地址是 A[0][1],而不是 A[1][0] 。
另外,无论是传统的 CRT 显示器、现代的 LCD 屏幕,还是摄像头的 CCD/CMOS 传感器,绝大多数图像硬件都是按照 “光栅扫描” 的方式工作的。电子束或读取电路首先扫描第一行的所有像素(从左到右),然后回扫到第二行开头,继续扫描第二行。由此可知,当数据从相机流出或发送到显卡时,数据流本身就是“一行接一行”的。使用行优先存储,可以直接将硬件缓冲区的数据 memcpy 到内存中,无需进行复杂的转置操作,效率最高。
以OpenCV为例来说,它最初就是个C语言的库,而且,还是一个专为图像处理而生的库,那么,结合上面这些内容,就不难推断它选择行优先存储的原因了。
而列优先存储的设计,则得从线性代数开始。
在线性代数中,向量经常被默认为列向量,例如线性方程组Ax=b中,x和b都是列向量。矩阵A也经常被看作是一组列向量的集合: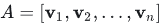 。这些都让列优先的存储成为了更加自然的选择。
。这些都让列优先的存储成为了更加自然的选择。
1957年诞生的Fortran,起初就是专为科学计算设计,设计者为了迎合上述的数学直觉,选择了列优先存储。于是,顺理成章的,从上世纪七十年代开始,用Fortran开发的现代科学计算的基石库BLAS 与 LAPACK,就自然用列优先的设计了。
而在八十年代诞生的Matlab,最初的目的就是作为 LINPACK 和 EISPACK(LAPACK 的前身)的交互式接口,以便学生使用,底层调用的全是 Fortran 编写的库,MATLAB 必须采用相同的数据布局以避免昂贵的内存转置操作(Transpose),即使后来 MATLAB 内核改用 C/C++ 重写,为了保持向后兼容性和对 BLAS/LAPACK 的高效调用,列优先的传统被保留了下来。
颜色数据紧密存储的设计,首先和行优先类似,也和显示器及图像传感器的工作方式有关,显示器每个像素在空间上就是由3种颜色的像素组成,图像传感器的感光像素在局部也是有3种不同颜色滤光片,所以,将不同颜色的像素数据紧密排列是符合“局部性原理”的高效做法。
不仅如此,许多常用的,针对彩色图像设计的算法,也需要同时访问单个像素的3个颜色通道数据,比如把彩色图转成灰度图的算法,以及各种颜色空间转换算法。
颜色数据按平面存储的设计,则更侧重于矩阵运算,不管是深度学习还是经典的线性代数有关的算法,在处理彩色图像的时候,其实都还是倾向于独立对每个颜色通道的数据进行处理,一个彩色图像,通常会被理解成R矩阵,G矩阵和B矩阵,需要分别对这3个矩阵进行处理。所以,同样按照“局部性原理”的话,按平面存储就是更优的设计了。
好了,现在你知道图像像素在内存怎么存了吧。
Related